Microsoft has finally announced the General Availability (GA) release of PowerShell 7.0. This represents a fairly significant milestone in PowerShell’s history. In this post, I’ll go through some of the history prior to this point, what’s new in this release and how it works in practice.
One of the common things I’ve seen in automation implemented by infrastructure teams is a lack of rigor around testing. That is to say, code that tests the task that is being automated is actually successful. A script could execute to its end without errors, but that doesn’t necessarily mean it actually did what it was supposed to.
This leads into a concern I’ve seen raised by stakeholders, about visibility of what is happening in an automation pipeline. One of the key stakeholders in this sort of security is the IT Security team, who often want visibility of certain outputs (like virtual machines) to determine if those are secure. In a couple of environments I’ve raised the idea of performing automated vulnerability scans on newly provisioned assets, as a way of ensuring what is delivered is at an acceptable level. By automating this task, we place no extra burden on those involved and ensure consistency.
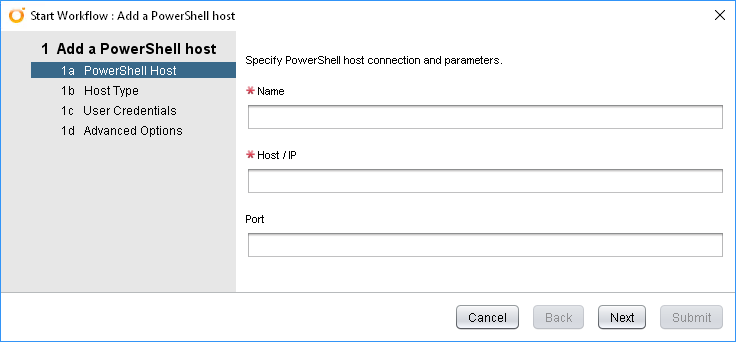
PowerShell Hosts are one of the types of endpoint available in vRealize Orchestrator’s Inventory. By having a PowerShell Host, you can leverage the breadth of PowerShell functionality from within your vRealize Orchestrator workflows. In this article, I’ll run through adding a PowerShell Host as well as some considerations from a technical and security point of view.
Adding A PowerShell Host
vRealize Orchestrator has a built-in Workflow for adding a Host under Library > PowerShell > Configuration. Run the “Add a PowerShell host” Workflow to start it. The opening interface is below:
Standing up a redundant/highly available database infrastructure can be one of the more complicated pieces of work. Doing it by hand is a long process with any points where errors could happen. It was with this in mind that I decided to use this as my first “project” with vRealize Automation.
When discussing redundancy or high availability (HA) for databases, there’s two distinct outcomes – firstly to ensure the continued delivery of the service in the event of infrastructure failure (the actual HA part) and secondly to ensure the data is kept in an orderly fashion (data integrity, no loss of data, etc). Where these two activities happen depend on the technology used.
In older versions of SQL Server, these outcomes were achieved using SQL Clustering. In SQL Clustering, the HA function was achieved at the server level by having 2 or more servers, while data integrity was maintained by the database residing on shared storage.