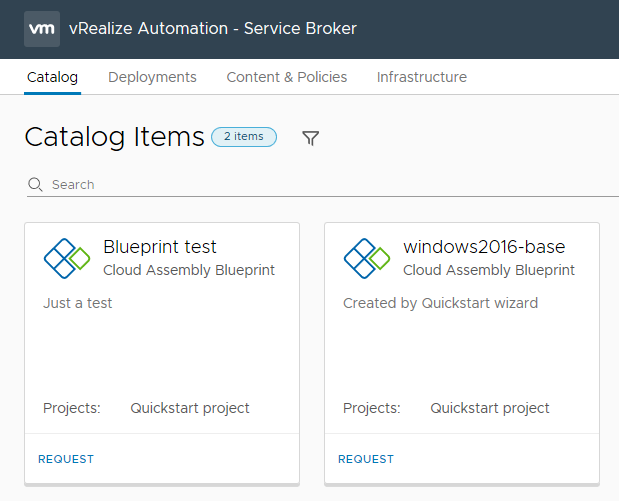
The Server Broker section of vRealize Automation 8 contains the items that your consumers will interact with the most – the Catalog, and the Deployments tab where they can review the status of their requests. It also has some administration areas, such as Content & Policies and Infrastructure
The Cloud Assembly section of vRealize Automation 8 is the one that vRA Administrators will most likely spend the most time. In vRA 7 terms, it constitutes aspects of the Infrastructure and Adminstration areas, plus the Blueprint Designer.
Infrastructure
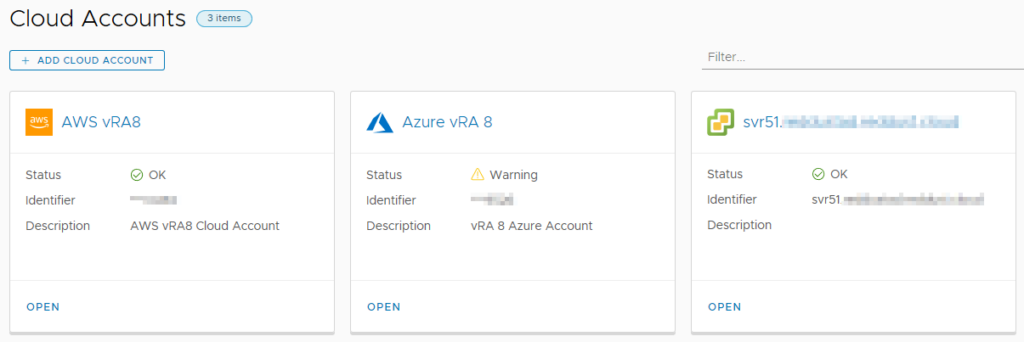
The Infrastructure tab contains the bulk of items relating to the configuration of vRA 8. The first item that most vRA administrators will have to head to is Cloud Accounts, under the Connections heading. This is where the account details for various public cloud and VMware offerings are configured. A typical scenario in this area could be vCenter and a couple of public clouds configured here.
Cloud Accounts already configured
The other item under Connections is Integrations, where a range of VMware and third party integrations can be added. By default, there will already be an entry for the embedded vRealize Orchestrator (vRO) instance.
Integration Options
The next section of interest is Configure, which contains the items of Projects, Cloud Zones, Kubernetes Zones, Flavor Mappings, Image Mappings, Network Profiles, Storage Profiles and Tags. Some of these are mentioned during the Guided Setup (as shown in the Getting Started post).
Network Profiles allow the creation of objects that control network behaviour and settings. The options that become available when creating a Network Profile depend on the Cloud Account selected. For AWS, the settings include the ability to create on-demand networks or security groups, and the selection of existing networks. Tags can also be applied. For vCenter-based Network Profiles, there are options to add IP ranges. When selecting existing networks to use, discovered items are shown with extra information. For AWS, this can include the CIDR or whether public IPs are enabled.
Storage Profiles control the way storage is provisioned for virtual machines. For vCenter Cloud Accounts, the standard set of settings are exposed, such as Storage policy, thin/thick provisioning, and datastore. For other Cloud Account types, the expected options are exposed.
Storage Profile options for AWS
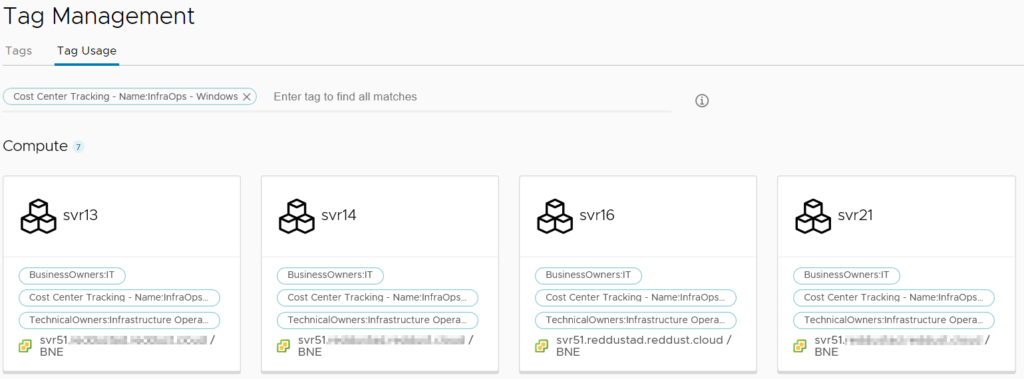
The Tags item lists all the tags discovered across all the Cloud Accounts. It’s then possible to select one or more tags and see what objects are currently assigned those tags. A good use case for this would be if a cost center tagging system was being used. It would be possible to see what resources a particular cost center is using across all platforms.
Tag Usage by the Windows Infrastructure Operations Team
The Resources section sits under Configure and has a by-type breakdown of all resource items that vRealize Automation can see. These items are Compute, Networks, Security, Storage, Machines, Volumes and Kubernetes. Compute lists high level abstractions of the compute capability in each Cloud Account and the administrator can’t do much in here except apply tags.
The Networks item has more content and actions available. It lists all networks discovered across Cloud Accounts. There’s also the ability to manage IP ranges, review individual IP addresses being managed, view load balancers and view “network domains”. These network domains are the top-level network object for each platform type (ie. for AWS, that would be VPCs).
The Security item lists only Security Groups that have been discovered. In the case of my configuration, this meant security groups from AWS. The only action that can be performed in this area is to add or remove tags.
Storage has three tabs – Storage Policies, Datastores/Clusters and Storage Accounts. The first two tabs are vCenter-focused, with Storage Policies listed the discovered policies. Tags can be managed on these policies. Datastores/clusters is has similar functionality, appearing to be mainly for informational and tagging purposes. Storage Accounts lists any defined Azure storage accounts and can be tagged.
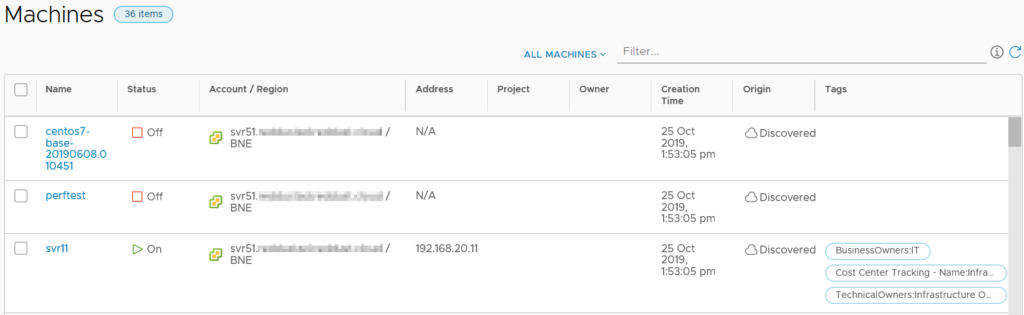
The Machines item lists all the machines across Cloud Accounts and includes information like status, IP address, Project, Owner and tags. There’s also the ability to filter the list by a variety of criteria.
The Machines list
Volumes lists all the “volumes” that have been discovered, which seems to include CD-ROM and floppy disk drives on vCenter VMs. Unfortunately the interface doesn’t list what machine the volume is attached to in the list view. It is possible to find this information by drilling down into the object.
The last area of any real interest under the Infrastructure tab is Onboarding. This area relates to creating “onboarding plans” for machines the vRA has discovered but isn’t managing. A benefit of this onboarding process is that vRA will create a blueprint based on the machines imported.
Extensibility
The Extensibility tab appears to share a lot of common elements with vRA 7, allowing the use of “Subscriptions” for triggering Orchestrator workflows. The menu items for this tab are shown below.
Extensibility menu items
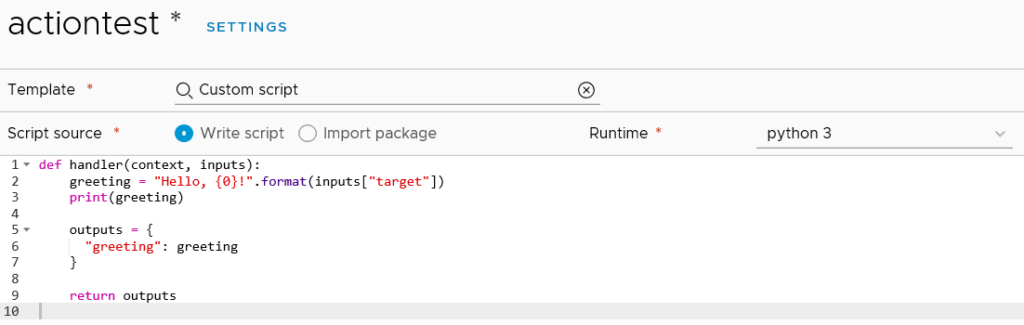
The Workflows item lists the 463 vRealize Orchestrator workflows that come with version 8, but it doesn’t seem to be anything to do in this area except look at them. The Actions item has no items listed, even though Orchestrator has over 400. Creating a new Action loads a code editor where the administrator can opt to write their code. By default, it seems to load the “Custom script” template which exposes the new ability to write python or nodejs code.
Action code editor
These Python-based scripts are part of the new “Action-based Extensibility” (ABX) that VMware have introduced in vRA 8. They are similar to how one might use vRealize Orchestrator workflows in vRA – to have automated tasks run at specific triggers. There is a reference in the documentation on ABX that suggests the code is actually run in the cloud, specifically using AWS Lambda. As such, an AWS subscription is required.
Marketplace
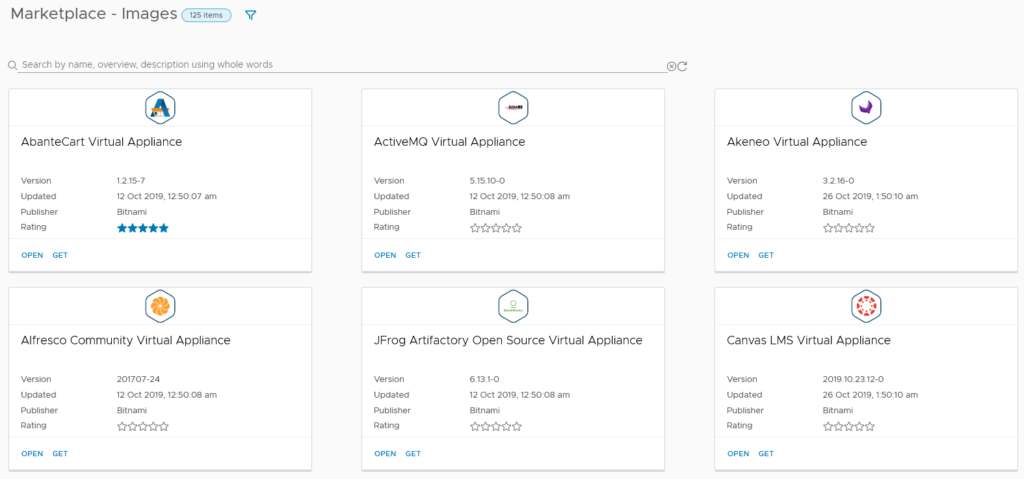
The Marketplace tab is an extended version of that which appears in Lifecycle Manager (LCM). It has three main areas – Blueprints, Images and Downloads. Images is a like-for-like match to LCM’s Marketplace content, containing virtual appliances from Bitnami and other vendors.
Marketplace Images
The Blueprints section is the more traditional blueprint items. Some are clearly designed for cloud-based deployments, such as one that uses AWS Redshift. Others are VMware-focused, relying on NSX. At the time of writing, only 18 blueprints are available.
Blueprints
The Blueprints tab represents a major area of use for infrastructure engineers and developers. This is where blueprints can be created, tested and reviewed. At a high level, the Blueprint Designer in version 8 has a lot of common elements with version 7.
vRA 8 Blueprint Designer
Two major changes are visible in the screenshot above. Firstly, with the Infrastructure-as-Code (IAC) approach in vRA 8, the actual code of the blueprint is shown on the right side. A lot of the detail defining in a blueprint is now performed in this code area, as opposed to GUI elements in version 7. The other major shift is the expanded range of components from cloud services. It’s now possible to have cloud services like AWS’s RDS or Lamba or Azure’s Key Vault directly on the blueprint.
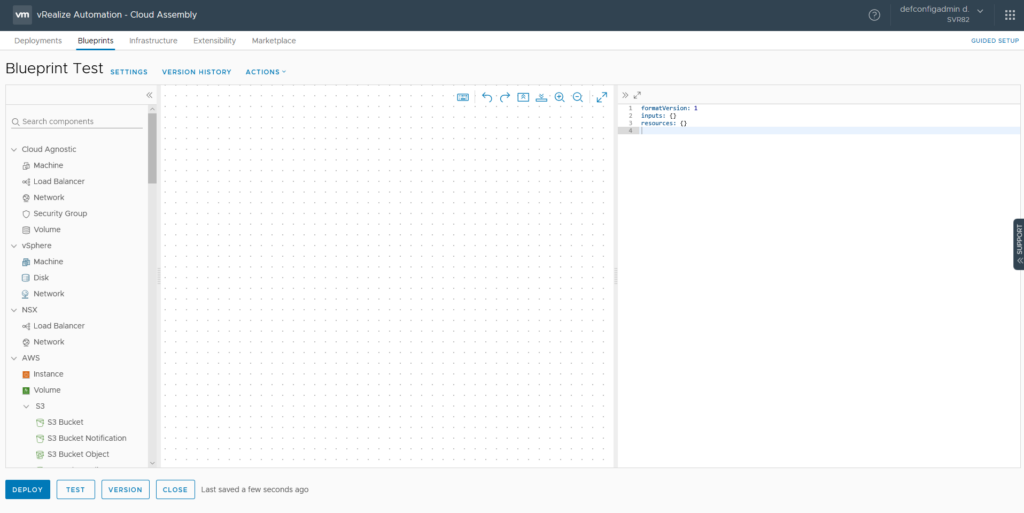
Verison 7 had a nested approach where certain objects could be nested inside of others. This seems to be gone now in version 8, with objects related to each other. A good example of this is the Configuration Management items like Puppet and Ansible. Adding items to the blueprint will generate a skeleton of code on the right side.
Generated code for a vSphere Machine component
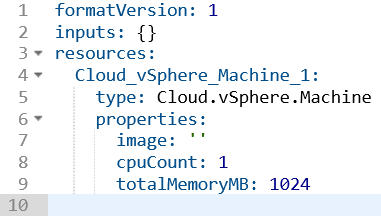
In some cases, a lightbulb will appear which assists in filling out the code. In the case of the vSphere machine, clicking this icon displayed a list of optional parameters that could be added. When using certain blueprint items, the fields that require values will show available options when clicking inside the quotes. For example, when clicking in the image or flavor properties for a Cloud Agnostic VM, Image and Flavor Mapping items will be listed.
Available values for Flavor
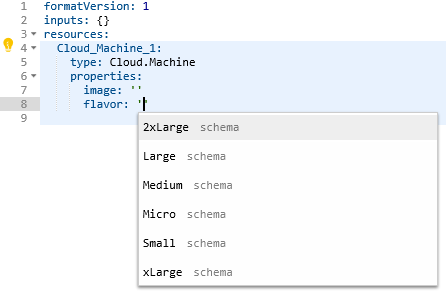
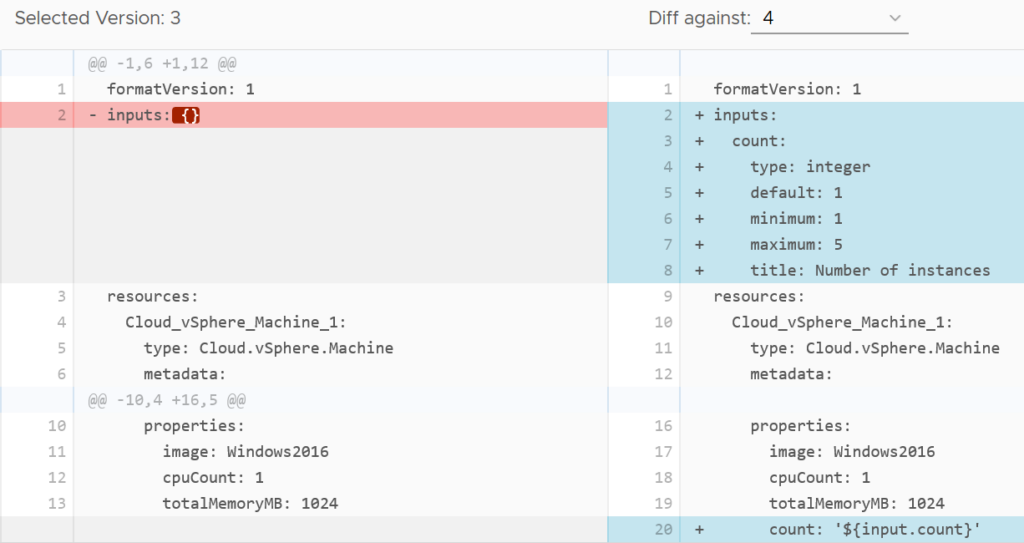
The code view also has real time syntax checking to point out errors. This helps ensure the code is valid and will work when deployed. It’s possible to define a number of inputs for a blueprint, removing the need to hardcode a lot of values. There’s a decent range of controls that can be applied to the inputs to prevent bad values being entered.
Defining a “count” input and binding the value
With the Infrastructure as Code focus, blueprints now have built in versioning support. This helps avoid the sort of thing I’ve seen in some organisations where version control is done by copying the blueprint repeatedly with an incrementing number in the name. With this proper versioning capability comes support tools like code diff.
Blueprint diff
Closing Thoughts
Now that I’m getting into the actual areas of day-to-day use of vRealize Automation 8, it’s clear that in some areas there’s a lot that’s changed under the hood and for the better. The versioning support is a good acknowledgement that there’s often more than just one vRA administrator in many organisations and it helps avoid that “stepping on each other’s toes” situation. The code-based approach for blueprints may be a change for some. Those who have already come from IAC backgrounds (especially AWS Cloudformation or Terraform) should feel very comfortable with the concepts in the code-based blueprints.
Towards the end of the Easy Install wizard for vRealize Automation 8 (vRA 8), a link is provided for the vRealize Automation 8 UI. Accessing this link will load a landing page that shows a short piece of text and a link to a login button.
vRealize Lifecycle Manager (LCM) is the first component installed by vRA 8’s unified “Easy Installer”. One of its primary functions is the deployment of VMware’s vRealize products. As mentioned in my Installation post, a link to the LCM UI appears towards the end of the installation process. The Dashboard of LCM has five items: Lifecycle Operations, Locker, User Management, Content Management and Marketplace
vRealize Automation 7 has been travelling along for a while now. While it’s now at a level of maturity, it’s always been a complicated application, even just in terms of infrastructure (with the need for Windows-based “IAAS” servers). vRealize Automation 8 would appear to represent a tipping point for a lot of things VMware has been working on in the background across multiple products and technologies.
The deployment architecture in vRA 8 represents a significant shift from prior versions. The installer deploys three virtual machines. These VMs will consume a total resource set of 12 vCPU, 44GB of RAM and about 246GB of disk space.
When VMware created the vRealize brand, they grouped together some of their most complex products under one banner. vRealize Automation (vRA) required the deployment and configuration of two components – a virtual appliance and a Windows server. The Windows server had a long list of prerequisites. In terms of operational management, using products like vRA meant ongoing work on scripts, workflows and other artifacts. The logical response to this is to create a non-production instance to protect your production instance. Moving updates to production could be achieved manually or via VMware’s Codestream product, but both approaches left a lot to be desired. vRealize Suite Life Cycle Manager (vRSLCM or just LCM) is a new approach to this set of problems.
Getting LCM Running
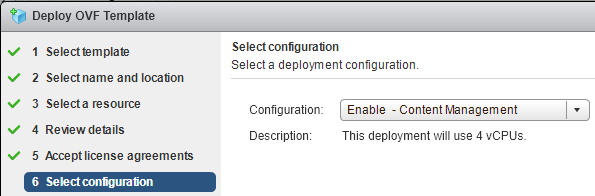
LCM comes supplied as a “Virtual Application” where a few configuration options are required to provision it. One of the LCM-specific settings is whether you want to enable the vaguely named “Content Management”. Enabling this will cause the appliance to use 4 processors instead of 2. Once the appliance is deployed and started, the rest of the configuration happens via the web interface.
Project Honolulu is Microsoft’s attempt at revamping the server administration experience. Historically the Windows server toolkit has been built around using numerous MMC (Microsoft Management Console) plugins – things like Event Viewer, AD Users and Computers and DNS Management are all built on MMC. We’ve seen a couple of attempts at revamping this in the past, there was Server Manager in 2008 and a refreshed form in 2012.
I suspect one of the driving forces behind Honolulu is the shift from RPC-based connectivity to WinRM for remote administration of servers. Honolulu seems to represent an alignment with this since it supports only Server 2012 onwards as nodes to manage, and its gateway component installs on Windows 10 or 2016. The documentation claims the management functions are performed using remote powershell or WMI over WinRM.
Installation
The installer for Project Honolulu is only about 30MB. While it supports installation on a system in a workgroup configuration, the TrustedHosts value for WS-Man needs to include the target nodes to be managed. The installer can do this for you or you can manually perform the commands to do it. On a domain joined system this isn’t required.
Starting Up Project Honolulu
Following install, the web interface will load with a tour splash screen. The main landing page is bare to start with.
Clicking on the Add button presents three possible options – a regular server connection, a fail-over cluster or a hyper-converged cluster. The first 2 options then allow the adding of single items or importing in bulk from a test file. The hyper-converged cluster option allows only single items. When adding in the server name or IP, Honolulu will appear to perform ongoing checking of the name to ensure it meets correct requirements and if it can connect with current credentials.
Single sign-on authentication is supported and is the default option. In the case of my test scenario, the system running Honolulu was in a workgroup and attempting to connect to domain based systems. For this, I manually specified credentials. One thing to note is it appears that even if a server is added using IP, the name will be resolved (perhaps by the initial connection) and subsequent connection attempts will fail if this name can’t be resolved by DNS. For domain-joined installations this should be a very rare case, in workgroup configurations it could happen. Honolulu will initiate its connections to the target node on the target’s port 5985. Assuming initial connection and authentication is successful, you should see a HTTP/1.1 Status 200 in a network capture. If everything is good, the status will have a tick and say “Online”. From there you can click on the server’s name, or select it and click Connect to drill down further.
Overview Page
The first page shown is an overview of the server and includes some metric graphs like CPU and RAM usage and the ability to shutdown or reboot the server remotely.
On the left is a collapsible menu of the other sections such as events, firewall, registry, processes, etc.
Tools
Some of the tools seem quite functional. The Events one allows filtering of the event log with a reasonable number of criteria and allows exporting. Files allows browsing of the target node’s file system with the ability to create folders, rename/delete and so on. The Process section looks to have all the main functions you would typically use in Task Manager, allowing remote termination of processes.
Closing Thoughts
Project Honolulu is an interesting tool from Microsoft. It seems capable of replacing the traditional Server Manager app that most Windows sytem administrators are familar with. I’ll be most interested in seeing how it develops in terms of extensions.
One of the first “killer applications” on the PC platform was Lotus 1-2-3, a spread sheeting program that greatly improved the productivity of the people using it and making a clear case for buying PCs. More recently, we’ve seen this sort of thing happening in IT infrastructure, with virtualisation, automation, cloud and “as a service”. VMware’s NSX product is the latest in a line of products from VMware in this sort of area.
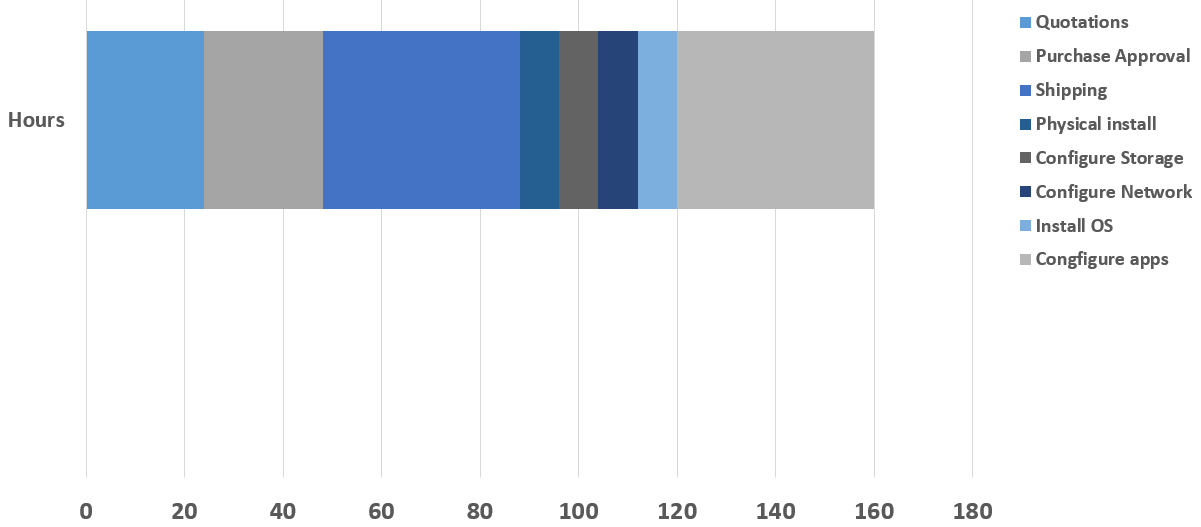
If we go back to the “good old days” of getting a server up and running, it could take weeks. The diagram below shows the amount of effort involved.
Old school server provisioning
While some of these numbers may have been more or less depending on circumstances, in many cases it could’ve taken over 150 business hours to get a server ready for use. Or almost a full month.
VMware Horizon is a Virtual Desktop Infrastructure (VDI) product which initially allowed provisioning of Virtual Desktops off a base image in an easily to manage fashion. Over time, VMware have added extra functionally, such as the ability to add Remote Desktop Services (RDS) servers.
Version 7 has added a number of interesting features and improvements. The one mentioned first in the release notes is Instant Clones. This is a technology I’ve been following for a while, ever since I read about it. Originally known as VMFork, it’s a technology to allow very rapid, almost instant, provisioning of Virtual Machines. Duncan Epping wrote a good overview of VMFork/Instant Clone back in 2014. Support for Virtual Volumes and Linux desktops are some of the other features that have been added.